|
Det här är ett avsnitt i en
webbkurs om databaser
som finns fritt tillgänglig på adressen
http://www.databasteknik.se/webbkursen/.
Senaste ändring:
18 juli 2005.
Av Thomas Padron-McCarthy. Copyright, alla rättigheter reserverade, osv. Skicka gärna kommentarer till webbkursen@databasteknik.se.
|
| Faktaruta: Ordet "index" kommer av det latinska ordet för pekfinger. Pekfinger heter också "index finger" på engelska. |
Ett index fungerar som registret i en bok. (Ett sånt register heter ju mycket riktigt "index" på engelska.)
Om du har en lärobok om databaser, och vill veta vad en databasadministratör gör, så kan du förstås börja på första sidan och sen läsa igenom hela boken tills du hittar avsnittet om databasadministratörer. Med tanke på hur tjocka typiska databasböcker brukar vara så tar det nog flera veckor.
Eller så kan du leta upp ordet "databasadministratör" i registret, och se att det står om databasadministratörer på sidan 717. Sen är det bara att bläddra fram till sidan 717, så hittar du databasadministratörsavsnittet där. Det sättet går naturligtvis mycket fortare än att läsa igenom hela boken. (När jag provade nu, med en databasbok som jag råkade ha med mig, så tog det 13 sekunder. Det är ju lite snabbare än flera veckor.)
Anledningen till att det går fortare är förstås att registret är sorterat i bokstavsordning. En annan anledning är att registret är mycket mindre än hela boken. Det är bara några få sidor att bläddra i, i stället för de många hundra sidorna i hela boken.
| Nummer | Namn | Adress |
|---|---|---|
| 4 | Lotta | Vägen 7 |
| 7 | Hjalmar | Vägen 7 |
| 60 | Diana | Slottet |
| 67 | Rex | Bengali |
| 107 | Saida | Allén 5 |
| 110 | Diana | Bengali |
| 113 | Hulda | Stora torget 18 |
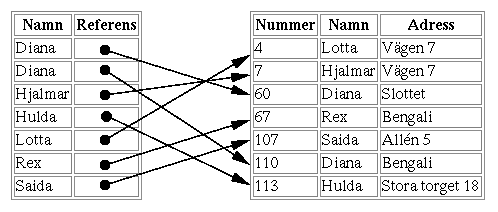
Raderna i tabellen är sorterade på kundnummer, så databashanteraren kan ganska snabbt hitta en kund med ett visst kundnummer. En sån här SQL-fråga går alltså ganska snabbt:
select namn, adress
from kund
where nummer = 7;
(Det här är bara ett exempel, Helge!
En tabell med sju rader är förstås väldigt liten,
och ingen databashanterare har problem med att hantera en
så liten tabell.
Databashanterarna bara skrattar åt vår löjliga tabell.
Men tänk dig i stället att det finns tusentals rader i tabellen,
eller kanske en miljard.)
| Faktaruta: I det här exemplet har vi bara sorterat raderna i tabellen. Riktiga databashanterare arbetar för det mesta med mer komplicerade lagringsstrukturer än så, som det går snabbare att söka i. B-träd och hashtabeller är två vanliga lagringsstrukturer. Men just nu nöjer vi oss, för enkelhets skull, med att ha raderna sorterade. |
Om vi vill söka efter en kund med ett visst namn, så har databashanteraren ingen nytta av att tabellen är sorterad på kundnummer. Då måste den läsa igenom alla raderna i tabellen, rad för rad (så kallad sekvensiell sökning). En sån här SQL-fråga går alltså ganska långsamt:
Vi kan därför använda kommandot create index för att skapa ett index som gör att man snabbt kan hitta en kund med ett visst namn. Man säger att man skapar ett "index på kolumnen namn", eller bara "index på namn".select nr, adress from kund where namn = 'Hjalmar';
(Kundnamn i kommandot ovan är bara ett namn, och indexet kan heta vad som helst.) Databashanteraren bygger nu en "extra tabell", som den använder internt när den ska söka efter namn i kundtabellen:create index kundnamn on kund(namn);
Eftersom indexet är sorterat på namn, går det snabbt att hitta "Hjalmar". Sen följer man bara referensen till rätt rad i kundtabellen, och där står den information om Hjalmar (nummer och adress) som vi ville ha fram.
Databashanteraren kommer automatiskt att använda det här nya indexet varje gång man ställer en SQL-fråga som söker efter namn i kundtabellen. Den kommer också automatiskt att ändra innehållet i indexet om man ändrar innehållet i kundtabellen, så att indexet hela tiden är aktuellt och pekar rätt.
| Faktaruta: Vanliga databashanterare lagrar sina data på hårddiskar. En hårddisk är indelad i diskblock. Ett diskblock innehåller ganska mycket data. När man läser data från hårddisken läser man alltid minst ett helt diskblock. Riktiga databashanterare brukar inte ha index som pekar ut enskilda rader i en tabell, som vi ritat i figuren ovan, utan de brukar i stället peka ut hela diskblock. |
Jo, databashanteraren skulle kunna skapa index automatiskt, kanske ett index på varje kolumn. Men alla indexen kanske inte behövs, och det finns också nackdelar med index:
(Databashanteraren skulle kunna samla statistik om de sökningar som görs, och sen skapa och ta bort index utifrån den statistiken. Men den sortens gissningar, som databashanteraren skulle göra, blir ganska grova jämfört med vad en människa kan åstadkomma. Till exempel vet databashanteraren inte vilka av de gjorda sökningarna som det är viktigt att de går snabbt, och vilka som kan få ta lite längre tid. Att skapa ett index kan också ta ganska lång tid, om det är stora tabeller, och man vill kanske inte tillåta databashanteraren att besluta om så stora jobb på egen hand.)
Databasadministratören, dvs den person eller grupp av personer som ansvarar för databasen, måste därför titta både på databasen och hur den ska användas, och sen bestämma index utifrån det. När databasen sen är i drift måste man förmodligen göra justeringar, både på grund av ändrade förutsättningar och på grund av att man inte lyckats perfekt med valet av index.
Det gäller alltså att bestämma vilka tabeller man ska skapa index för, och på vilka kolumner. Ofta är det en avvägning mellan att ha index (för att sökningarna ska gå snabbare) och att inte ha index (för att spara plats och för att ändringar i databasen ska gå snabbare).
Man kan följa de här stegen:
Här kan kolumnerna namn och jobbarpå i tabellen "anställd", och kolumnen avdnr i tabellen "avdelning", vara lämpliga kandidater till att ha index. Kolumnen adress i tabellen "anställd" används bara i svaret, och behöver därför inget index. (Övning: Varför behöver kolumner som bara används i svaret inget index? [Svar])select anställd.namn, anställd.adress from anställd, avdelning where anställd.namn = 'Bengt' and anställd.jobbarpå = avdelning.avdnr
Det tar kanske en minut. Då kan det vara bättre att lagra summan separat, och sen se till att uppdatera den varje gång man ändrar i tabellen med svenskar. I en aktiv databas kan man definiera regler, som ser till att databashanteraren automatiskt gör den uppdateringen varje gång tabellen med svenskar ändras.select sum(lön) from svensk
Ett exempel: En enskild sökning går snabbt, på 20 millisekunder (0.02 sekunder). Men nu kommer det tusen användare per sekund och gör en sån sökning. Eftersom varje sökning tar 0.02 sekunder för databashanteraren att göra, skulle databashanteraren nu behöva arbeta 0.02 * 1000, dvs 20 sekunder, varje sekund. Annorlunda uttryckt skulle databashanteraren behöva vara 20 gånger snabbare för att precis hinna med alla sökningarna. I stället för 0.02 sekunder får användarna nu kanske vänta i minuter eller timmar på svaret. Den som försökt betala räkningar via en Internet-bank i slutet av en månad känner igen fenomenet. Det blir så att säga "lång kö till kassan".
(Notera: Jag har gjort vissa förenklingar. Ett databassystem som körs på en dator med flera diskar och flera processorer, så att flera sökningar kan göras samtidigt, eller där resultatet av en sökning kan användas som svar även på andra sökningar, kan hinna med.)
För att upptäcka den här sortens problem kan man göra en belastningsanalys. Då försöker man räkna ut belastningen på databasen, det vill säga hur många operationer som utförs per tidsenhet i databasen, eller i en del av databasen, till exempel en tabell eller en hårddisk. Till exempel kan man titta på hur många läsningar som görs per sekund från hårddisken. Man måste ta hänsyn till
För att göra en rättvisande belastningsanalys krävs det ganska goda kunskaper om exakt hur databashanteraren arbetar internt. Därför är det vanligare att man helt enkelt provkör och ser hur mycket databashanteraren hinner med.
Men även en enkel belastningsanalys kan ge värdefulla ledtrådar till om en tänkt databaslösning är realistisk. Kanske kommer vi fram till att databasen kommer att göra en miljon läsningar i sekunden från en viss tabell som ligger lagrad på hårddisken. Om varje läsning tar 10 millisekunder, dvs 0.01 sekunder, skulle hårddisken behöva arbeta 0.01 * 1000000, dvs 10000 sekunder (ungefär tre timmar) per sekund. Annorlunda uttryckt: Hårddisken skulle behöva vara 10000 gånger snabbare för att precis hinna med. Vi bör därför fundera lite på om vi verkligen ska försöka bygga systemet på det sättet.