Distribuerade databaser
En databas är en samling data som hör samman på något sätt.
En distribuerad databas är en samling data som hör samman på något sätt,
och där dessa data är fysiskt utspridda på flera olika datorer
som är sammankopplade med ett datornät.
Ett distribuerat databashanteringssystem
är det program, eller system av program, som hanterar den distribuerade
databasen.
På engelska kallas det ibland
DDBMS eller Distributed Database Management System.
Motsatsen till en distribuerad databas är en
"vanlig" eller "centraliserad" databas.
Vad är en distribuerad databas?
Man brukar skilja på följande olika typer av system,
som alla är relaterade genom att datornät är inblandade:
- En vanlig centraliserad databas som man kan komma åt via ett datornät.
Det här är förstås ingen distribuerad databas, eftersom alla data lagras
och hanteras av en enda dator.
- Klient/server-system, som har alla data lagrade på ett ställe,
servern, eller, med ett försök till svensk term: betjänten.
Klienterna är de program som användarna arbetar med,
och de skickar frågor och uppdateringar till servern.
Termen "server" används både om programmet som hanterar data
och kommunicerar med klienterna, och om datorn som det programmet körs på.
Termen "klient" brukar huvudsakligen användas om programmen.
Nästan alla stora, moderna databashanterare (Oracle, SQL Server osv)
är byggda som klient/server-system.
Ett klient/server-system är inte heller det någon distribuerad databas,
eftersom alla data lagras av en enda dator.
- Orelaterade eller löst relaterade distribuerade mängder av data,
till exempel World Wide Web.
En sådan datamängd är ingen distribuerad databas, och ingen databas överhuvudtaget,
eftersom dess data inte hör samman.
- En multidatabas är flera självständiga databaser,
som är sammankopplade så att man kan ställa frågor som hämtar data
ur flera databaser på en gång.
I frågorna måste man ange vilka databaser uppgifterna ska hämtas från,
och den som skriver frågan måste alltså veta i vilken databas som varje uppgift finns.
Multidatabaser kan kallas för distribuerade databaser,
men ofta brukar man med det mena mer integrerade system enligt nedan.
- "Riktiga" distribuerade databaser,
som erbjuder placeringstransparens.
Det betyder att man kan skriva frågor som om det var en vanlig centraliserad databas,
utan att behöva ange var databashanteraren ska hämta data ifrån.
För att klara detta måste databashanteraren ha en hårdare kontroll över var data lagras,
och det måste finnas ett globalt schema, som beskriver hela databasens uppbyggnad.
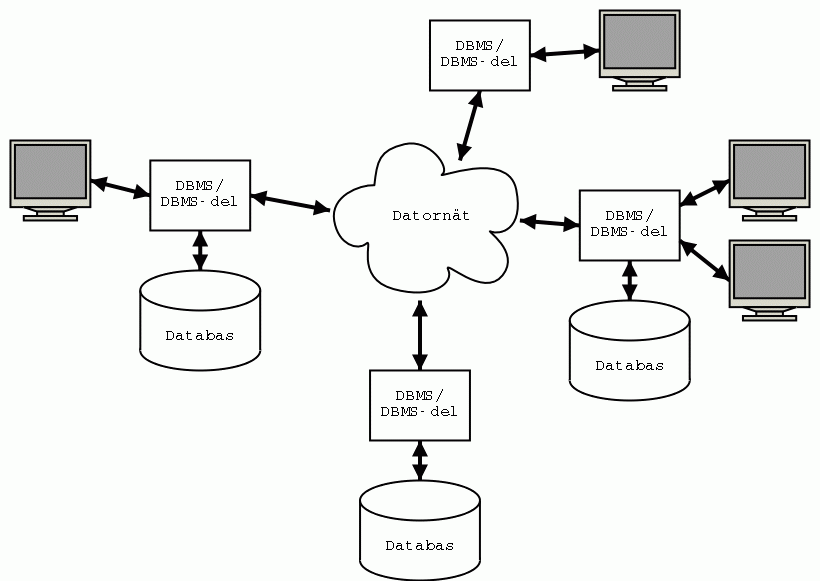
Här är en bild som ska illustrera att data i en distribuerad databas
är utspridda på olika ställen,
och att det går att komma åt dem via datornätet:
Fördelar och nackdelar
Fördelar med distribuerade databaser, jämfört med ett centraliserat system:
- Man kan få högre tillförlitlighet och tillgänglighet,
åtminstone med lämpligt vald redundans i systemet.
Om de data man söker inte går att hämta från ett visst ställe,
exempelvis för att just den datorn är nere just nu,
så kanske de går att hämta från något annat ställe.
(Men med en olämplig design kan det i stället bli tvärtom, i värsta fall så
att precis alla maskiner som ingår måste vara igång för att man ska kunna
göra något alls.)
- Man kan få bättre prestanda, dvs att frågorna går snabbare att köra,
i och med att de kan delas upp och köras parallellt på flera maskiner.
(Men med en olämplig design kan det i stället gå långsammare,
eftersom data ska skickas fram och tillbaka över datornätet.)
- Systemet blir lättare att expandera än ett centraliserat system,
med bättre skalbarhet.
Om min centraliserade databas blir för långsam
(och vi redan har valt lämpliga fysiska lagringsstrukturer),
så måste vi kanske byta ut den stora, dyra serverdatorn mot en ännu större och dyrare.
I ett distribuerat system, som redan består av flera datorer,
räcker det kanske att köpa en till (förhållandevis billig) dator, och koppla in den.
- För naturligt distribuerade tillämpningar kan en distribuerad databaslösning
passa bättre. Till exempel kanske ett företag med lokalavdelningar vill låta varje
lokalavdelning lagra sina data lokalt, men man ska ändå kunna göra sökningar
i hela företagets datamängd.
- I en distribuerad databas är det lättare att ha lokal kontroll av data,
till exempel så att varje avdelning inom företaget behåller kontrollen av sina data,
och kan bestämma vilka sökningar och ändringar som resten av företaget får göra.
- Vid sammanslagning av databaser kan man ha nytta av multidatabasteknik.
Om två företag går samman har de ofta databaser sedan tidigare,
och det kan vara svårt att ersätta dem med ett gemensamt, integrerat system.
Då kan man i stället behålla de gamla systemen, men samla dem i en multidatabas
så att man kan söka i flera databaser på en gång.
Det finns också nackdelar med distribuerade databaser:
- Säkerheten kan bli sämre.
Det kan vara svårare att skydda sina data mot obehörig åtkomst.
Data ska ju skickas över ett nätverk, som kan avlyssnas,
och vem vet vilka skumma typer som finns på lokalkontoret i Oslo och snokar i de
data som vi lagrat där.
- Eftersom distribuerade databaser är en nyare teknik, och mindre vanliga,
än centraliserade databaser, kan det vara svårt att få tag i personer
med erfarenhet och kompetens som kan konstruera och administrera databasen.
- Det är också svårare att bygga en databashanterare för distribuerade databaser:
- Kommunikationen mellan de olika datorerna via datornätet tillkommer.
- Databashanteraren måste hålla reda på var data finns,
om en del data finns i flera kopior, och i så fall var.
- Det blir svårare att köra frågorna,
eftersom data och kanske också delar av frågor ska skickas
fram och tillbaka mellan olika maskiner.
- Frågeoptimeringen, dvs att välja ett snabbt sätt att köra frågan,
blir mer komplicerad än i en centraliserad databas.
- Transaktionshantering,
med kontroll av samtidig åtkomst och återhämtning (recovery) efter krascher,
blir mer komplicerad än i en centraliserad databas,
eftersom man måste upprätthålla konsistensen mellan data på olika maskiner.
Design av distribuerade databaser
När man konstruerar en vanlig, centraliserad databas brukar man börja
med att göra en konceptuell beskrivning, till exempel ett ER-diagram.
Sen översätter man den konceptuella beskrivningen till den datamodell
som databashanteraren använder, oftast relationsmodellen med tabeller.
Till slut väljer man fysiska lagringsstrukturer.
I fallet med en distribuerad databas tillkommer ett steg till,
nämligen att bestämma
- fragmentering, dvs hur data ska delas upp,
- placering, dvs var de olika delarna ska placeras,
- replikering, om vissa data ska finnas i flera kopior.
Fragmentering kan göras per tabell (eller motsvarande),
så att en tabell lagras helt och hållet på en viss dator.
En tabell kan också delas upp och lagras på olika ställen,
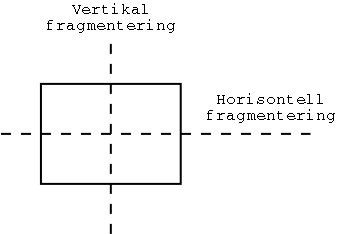
och då brukar man skilja mellan horisontell och vertikal fragmentering.
Vid horisontell fragmentering delar man tabellen med ett eller flera
"horisontella streck", och placerar hela rader på olika platser.
Vid vertikal fragmentering delar man i stället upp tabellen med "vertikala streck",
och placerar kolumnerna på olika ställen.
Normalt är det inte någon person som sitter och bestämmer att den här
raden ska hit och den där raden ska dit, utan databashanteraren
har fått en uppsättning regler som talar om hur det ska göras.
De reglerna utgör ett fragmenteringsschema och samtidigt att
placeringsschema.
På samma sätt kan man tala om ett replikeringsschema.
Litteratur
Det finns även mer specialiserad litteratur. Här är en grundbok om
distribuerade databaser: